ML08 | 多分类问题训练:IRIS鸢尾花分类问题
Javascript玩转机器学习08
多分类问题
-
手写数字分类:10种分类
-
图片分类:成千上万种分类
-
多种特征:需要多层神经网络
-
多种分类输出:需要在输出层加softMax函数
鸢尾花(iris)分类问题
- 著名的数据集,诞生了很久,被无数科学家用来验证自己的算法
- 三种分类(输出):山鸢尾,变色鸢尾,Virginica鸢尾
- 四种特征(输入):花瓣长、宽、花萼长、宽
加载IRIS数据集(训练集与验证集)
- 用脚本生成IRIS数据集:训练集+验证集
//生成:训练集特征,训练集标签,验证集特征,验证集标签(数据类型为tensor)
const [xTrain,yTrain,xTest,yTest] = getIrisData(0.15);
xTrain.print();
yTrain.print();
xTest.print();
yTest.print();
console.log(IRIS_CLASSES);- 打印结果:

定义模型结构:带有softMax激活函数的多层神经网络
- 初始化一个神经网络模型
//初始化模型
const model = tf.sequential();- 为模型添加两个层
- 设计层的神经元个数、inputShape、激活函数
//添加隐藏层:全链接层
model.add(tf.layers.dense({
units:10, //10个神经元,超参数
inputShape:[xTrain.shape[1]],
activation:'sigmoid',
}));
//添加输出层:全链接层
model.add(tf.layers.dense({
units:3, //必须是输出类别的个数
// inputShape:[yTrain.shape], //除了第一层以外 都不需要设计inputShape,会根据上一层的输出自动设计
activation:'softmax', //softmax 激活函数 适用于多种分类输出层
}));交叉熵损失函数
- 交叉熵损失函数 Cross-Entropy:是LogLoss对数损失函数的多分类版本,都用于度量分类神经网络模型的性能。
- 当分类数为2时,交叉熵损失=对数损失。

定义损失函数、优化器、准确度度量
//设置损失函数,增加训练过程中的“准确度”度量
model.compile({
loss:'categoricalCrossentropy',
optimizer: tf.train.adam(0.1),
metrics: ['accuracy']
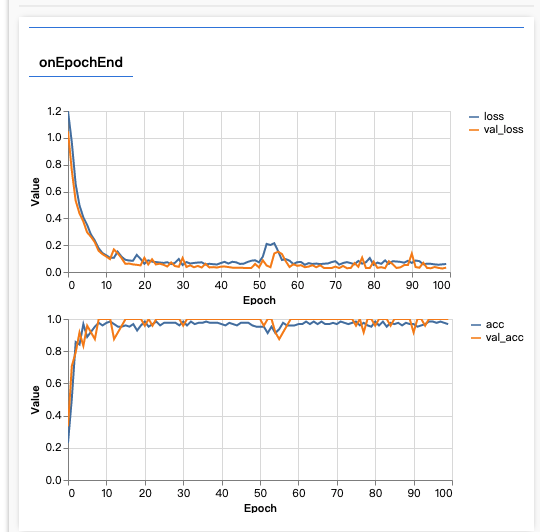
});训练模型并可视化
//训练并可视化
await model.fit(xTrain,yTrain,{
epochs:100,
validationData:[xTest,yTest],
callbacks:tfvis.show.fitCallbacks(
{name:''},
['loss','val_loss','acc','val_acc'],
{callbacks:['onEpochEnd']},
),
})- 训练过程:
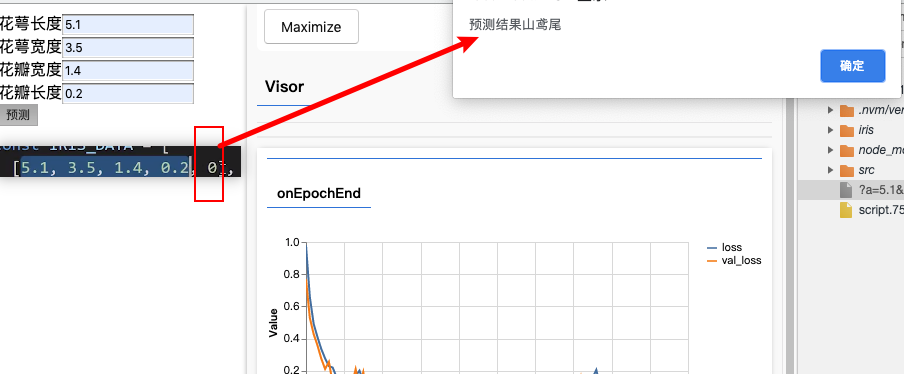
模型多分类预测
window.predict = (form)=>{
const input = tf.tensor([[
form.a.value * 1,
form.b.value * 1,
form.c.value * 1,
form.d.value * 1,
]]);
debugger;
const pred = model.predict(input);
pred.print();
alert(`预测结果${IRIS_CLASSES[pred.argMax(1).dataSync(0)]}`);
}
上次更新: