ML05 | 归一化
Javascript玩转机器学习05
归一化:
- 将大数量级
特征转化到较小的数量级下,通常是[0,1]或[-1,1]
为什么要归一化:
- 绝大多数TensorFlow.js的模型都不是给特别大的数设计的
- 将不同数量级的
特征转换到统一数量级,避免某个特征影响过大
归一化任务实例-身高体重预测:
- 准备身高体重数据,可视化
//模拟标签和特征
const heights=[150,160,170,180];
const weights=[40,50,60,70];
//可视化数据
tfvis.render.scatterplot(
{name:'身高体重预测'},
{values:heights.map((x,i)=>({x,y:weights[i]}))},
{
xAxisDomain:[140,190],
yAxisDomain:[30,80],
}
)- 用TFJS的API
归一化数据
//将数据转换为tensor 并归一化
const inputs = tf.tensor(heights).sub(150).div(30);
const labels = tf.tensor(weights).sub(40).div(30);
inputs.print();
labels.print();- 归一化后数据:
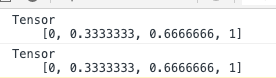
- 训练模型并预测
//创造一个连续模型
const model = tf.sequential();
model.add(tf.layers.dense({units:1,inputShape:[1]})); //添加一个全连接层(点乘权重+偏置)
model.compile({loss:tf.losses.meanSquaredError,optimizer:tf.train.sgd(0.1)}); //设置:损失函数为均方误差MSE,优化器为随机梯度下降SGD,学习速率为0.1,学习率是一个需要调整优化的超参数
await model.fit(inputs, labels, {
batchSize: 4, //批量训练的数据集大小(超参数,需要不断调整试验)
epochs: 100, //迭代实验次数(超参数,需要不断调整试验)
callbacks: tfvis.show.fitCallbacks({ name: "训练过程" }, ["loss"])
});
//将待预测数据190转为Tensor,用训练好的模型进行预测
const output = model.predict(tf.tensor([190]).sub(150).div(30));
output.print();- 将结果反归一化为正常数据
//将输出的Tensor反归一化并转为普通数据并显示
alert(`如果身高是190cm,预测体重为${output.mul(30).add(40).dataSync()}kg`);- 预测结果:

- 上述例子中,归一化的关键步骤就是:
减去 min(最小值)
除以 diff(最大值最小值的差)- 反归一化的关键步骤就是归一化的反操作:
乘以 diff
加上 min
上次更新: